Open-Source Software
Full-Web Access and AI-Powered
Open-Capture is a document capture and automated processing software solution combining OCR and AI, machine learning, to extract data and export it to third-party management software. A free and open-source solution distributed under the GNU General Public License v3.
Published by Edissyum, expert in ECM, document management and BPM
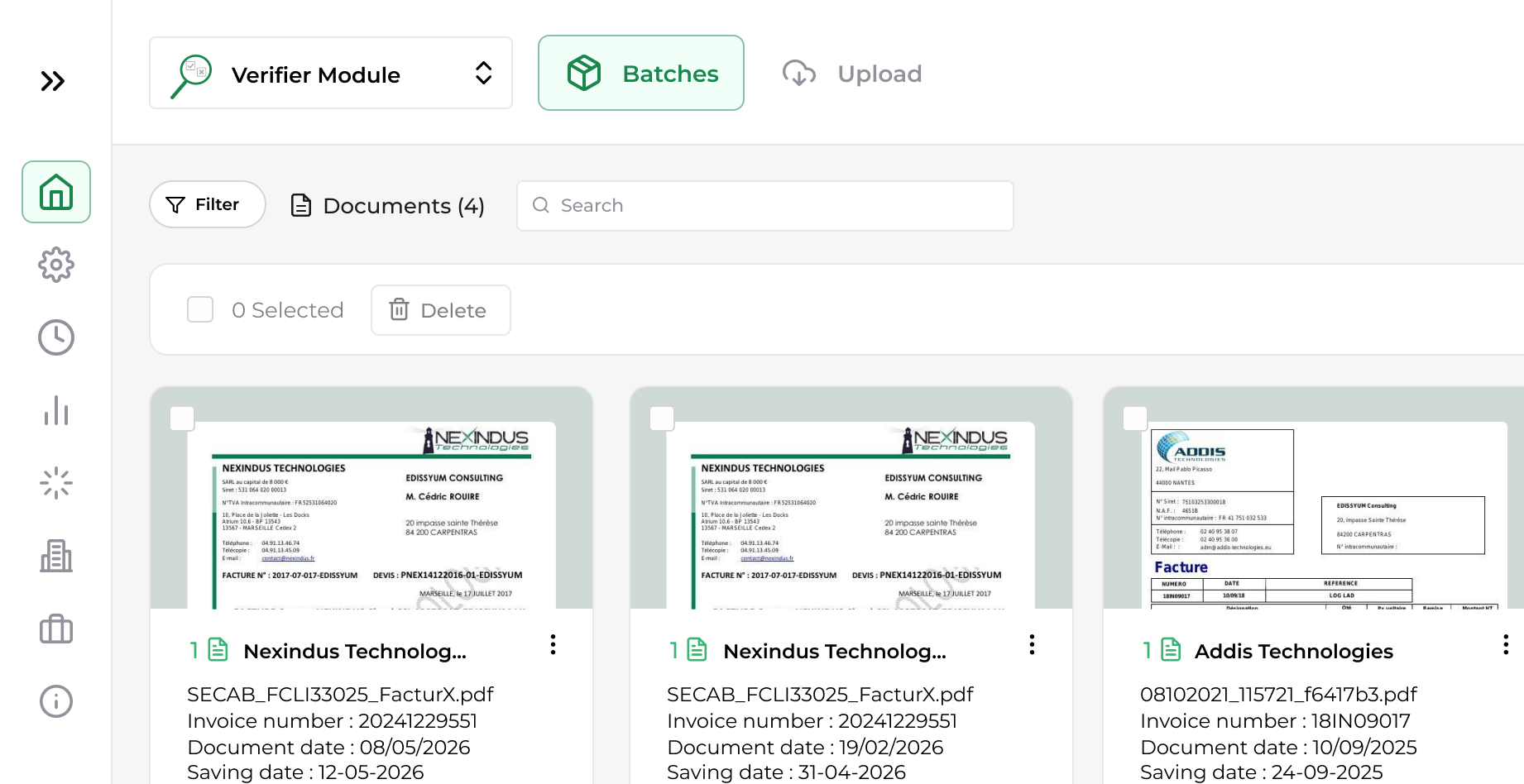
Capture and process all types of documents from all your sources
Separation, sorting, bundling and unbundling of documents
Automated document capture
Open-Capture automates the acquisition of paper and digital documents to simplify their processing. The platform handles content capture, data extraction and file conversion.
Advanced processing technologies
The solution relies on technologies such as OCR, machine learning, regular expressions and open APIs to improve document reading, analysis and use.
Multi-channel collection
Files can be captured automatically from scanners, multifunction copiers, emails, attachments or web forms, then injected into a processing workflow.
Flexible and configurable workflows
Workflow settings, capture rules and scripts make it possible to create processing scenarios tailored to each organization’s needs.
Export and integration
Processed documents and data can be sent to network folders, ECM systems such as Alfresco or SharePoint, or exported as PDF, PDF/A, XML or plain text.
Performance and time savings
Open-Capture can process large document volumes quickly thanks to simple administration, fast deployment and automation of recurring tasks.
1 %
OCR Success
1 h
Time saved
1 %
Deadlines respected
Acquisition
Extraction
Verification
Exportation
Document acquisition
Capture, acquisition and sorting of documents from multiple sources, including separation, sorting, bundling and unbundling operations.
Scanners
Multifunction copiers
File drop
Emails and attachments
Upload interface
Web services
Data extraction and classification
Automated extraction of information using OCR, pre-trained models and document classification mechanisms.
Tesseract OCR
Pre-trained models
Key-value extraction
Matching through reference data
Data dictionaries
Barcode and QR code reading
Verification and validation
The platform checks the consistency and validity of extracted fields using simple or advanced rules.
Compliance with extraction rules
Format validation
Validation against reference data
Advanced business rules through scripts
Export and distribution
Documents and data are distributed to ECM, workflow or archiving tools according to your needs.
Native MEM Courrier connector
CMIS connector
OpenADS / Oxalis
OpenCRM
PDF, XML, CSV
Web services
An open-source technology designed for document capture
Open-Capture is a full-web IDR software solution developed by our teams in React and Python. It integrates several open-source building blocks for reading, analysis, classification and document distribution.
Tesseract OCR
Supervised AI and pre-trained models
Machine learning classification
100% web application
Native Linux operation
Open and extensible technology
No limit on the number of users
Additional modules available
Nous utilisons des cookies pour vous garantir la meilleure expérience sur notre site web. Si vous continuez à utiliser ce site, nous supposerons que vous en êtes satisfait.
Vous pouvez révoquer votre consentement à tout moment en utilisant le bouton « Révoquer le consentement ».