Numérisation en masse et préparation intelligente des lots documentaires
Le module Splitter pour Open-Capture permet de numériser, organiser et préparer des lots de documents avant leur extraction. Il facilite la séparation automatique, la classification des documents et l’enrichissement des métadonnées pour rendre les traitements plus rapides et plus fiables.
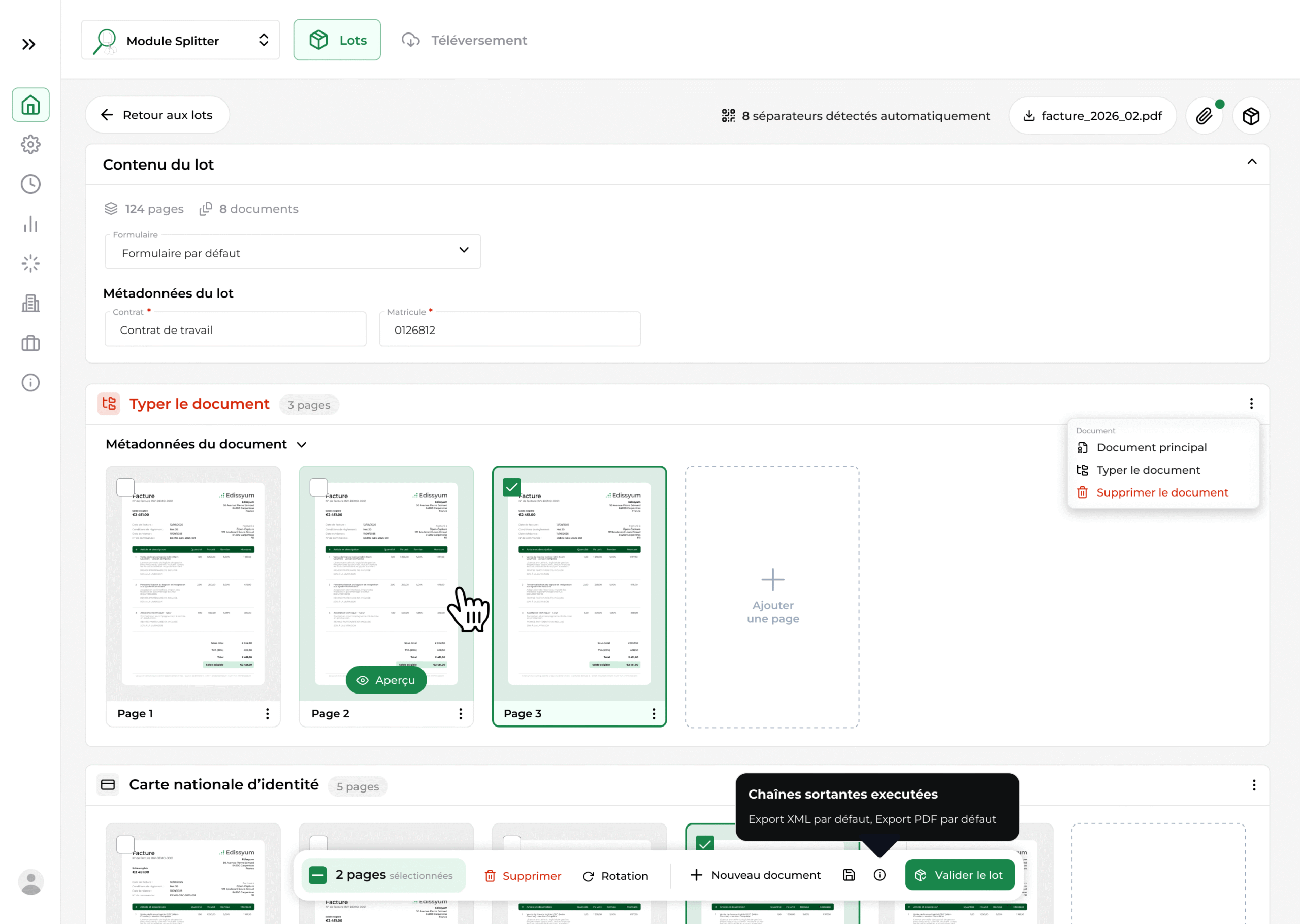
Préparer les lots documentaires avant extraction
Le module Splitter pour Open-Capture est conçu pour la numérisation en masse et la préparation des lots de documents. Il facilite l’organisation des fichiers avant traitement, la séparation automatique des documents et l’enrichissement des métadonnées pour rendre l’extraction plus fiable.
Grâce aux fonctions de classification et d’apprentissage, Splitter identifie les types de documents, simplifie le tri et améliore les traitements de capture et de RAD.
Numérisation en masse
Prépare de grands volumes de documents pour un traitement structuré et plus fluide.
Préparation des lots
Organise les documents avant extraction avec gestion des lots, des pages et des métadonnées.
Contrôle des images
Permet de vérifier rapidement les numérisations grâce aux vignettes, au zoom et aux outils de correction.
Classification intelligente
Identifie automatiquement le type de document pour faciliter le tri et l’indexation.
Séparation automatique
Découpe les lots selon des critères visuels, des ruptures documentaires (par exemple le numéro de page ou bien encore une combinaison numéro de document + numéro d’émetteur etc..) ou des QR codes.
Enrichissement des métadonnées
Ajoute le typage documentaire et les informations utiles pour les traitements en aval.
Splitter met à disposition plusieurs fonctions pour structurer les lots avant extraction et améliorer la qualité du traitement documentaire.
- Des outils pour organiser et préparer les documents
- Création et suppression de lots
- Création et suppression de lots
- Redressement d’image
- Réorganisation des documents
- Typage documentaire
- Enrichissement des métadonnées
Grâce aux fonctions de Machine Learning, Open-Capture Splitter reconnaît automatiquement le type de document soumis. Cette classification améliore le tri, la séparation et l’indexation des lots, tout en optimisant les traitements de RAD.
Splitter facilite la préparation des documents avant extraction, réduit les manipulations manuelles et améliore la qualité du traitement sur les flux de numérisation en masse.